Good project organisation is essential for collaboration, transparency, and reproducibility in any data analysis project. A well organised project sets a strong foundation for reliable data analysis, ultimately saving you time and reducing the risk of errors.
This module introduces practical strategies to organise your workflow and files. You will learn how to create and use R Projects, understand relative and absolute file paths, and structure your work for clarity and reproducibility.
R Projects
R Projects are an RStudio feature that can help you organise all files related to a single project folder and access them in a project specific workspace.
Using an R Project in RStudio helps with:
- Automatic working directory: When you open an R Project, RStudio automatically sets the working directory location to the project’s folder. The working directory is the folder relative file paths are built from (more details later).
- Project settings: The
.Rprojfile created when you make an R Project stores project-specific settings and keyboard shortcuts (e.g., git, packages, or documents). These settings are automatically loaded when you open the project in RStudio. - Workspace restoration: When you reopen an R Project, Rstudio will reload your workspace (scripts, unsaved changes and history) exactly how you left it.
- Folder structure: R projects make it easy to access related files in the project folder with relative paths, making your analysis easier to share with others.
Create an R project
- Click the project drop-down in the top-right corner. Then click on the “New Project…”.
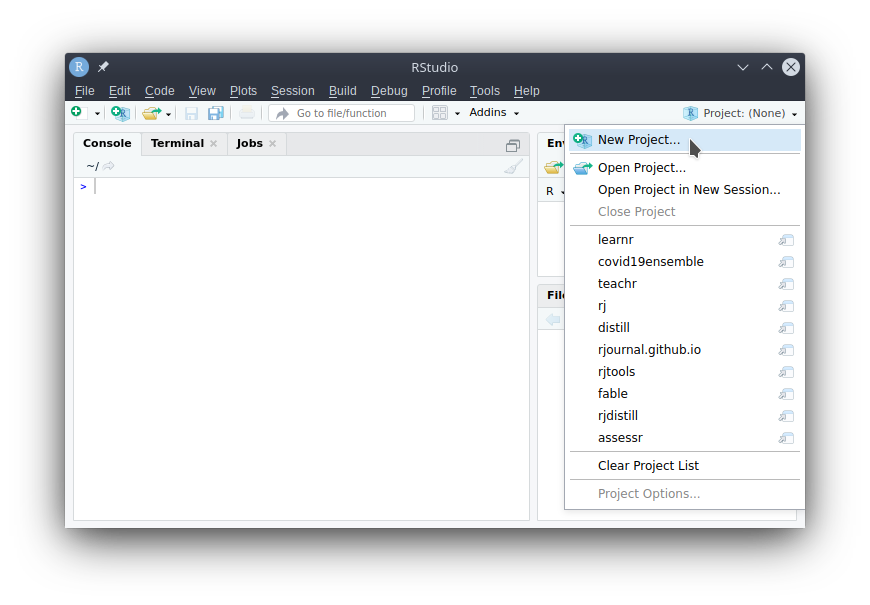
- It will show you three options.
- New Directory: Start from scratch with a new empty folder for your project.
- Existing Directory: If you’re already started some work without a project, convert that folder into a project.
- Version Control: If your work already exists elsewhere as a git or svn repository (such as GitHub), this will download the work and create a project for it.
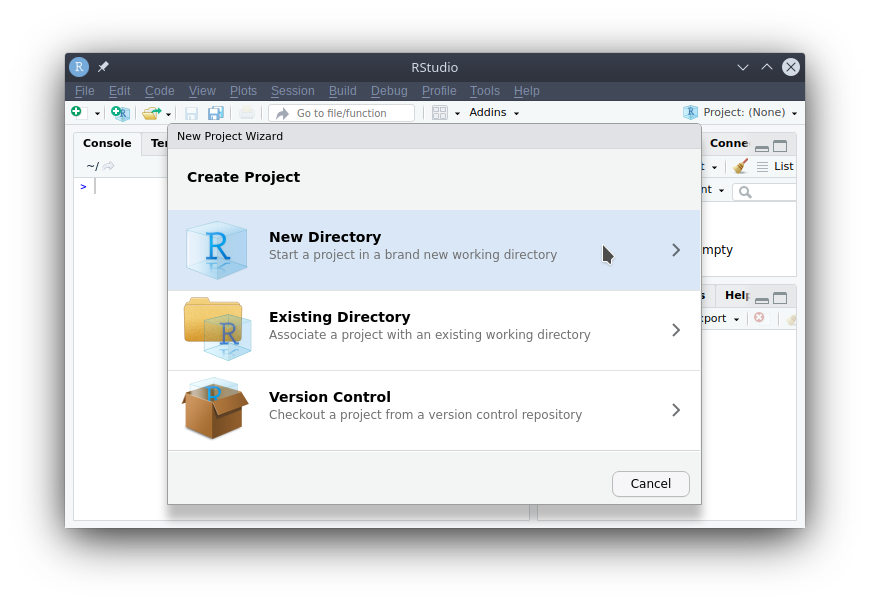
- There are many different types of R projects that you can create. These various project types come bundled with starter code and settings (for shortcuts and build options). A standard project (without any boilerplate or settings) is suitable most projects - so simply select “New Project” for an empty folder.
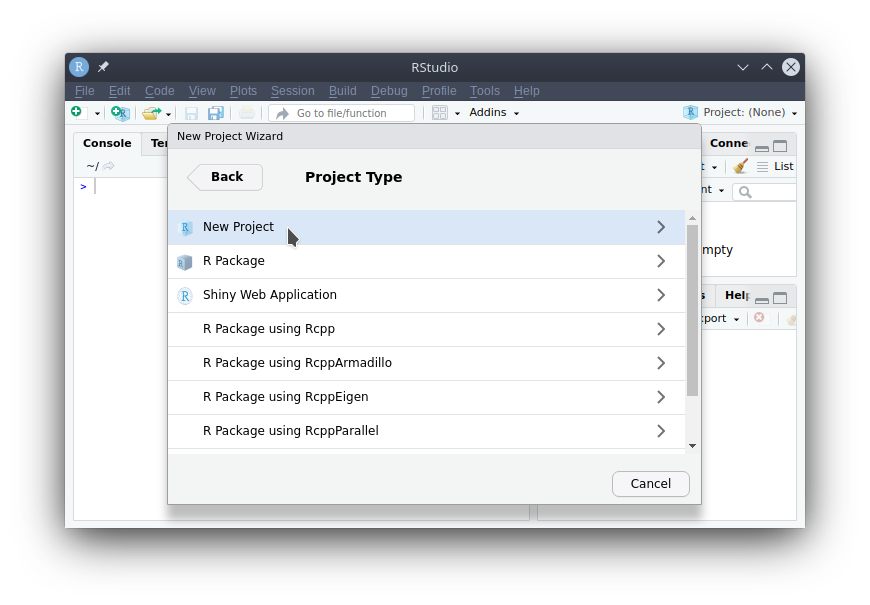
- Give your project (and the folder containing it) a name using the “Directory name:” field. You can also choose where the project will exist on your computer by clicking on the “Browse…” button. If you do not choose, it will be in your home folder (
/home/<username>on macOS, andC:/Users/<username>on Windows). You can leave the rest (git and renv) unchecked for now.
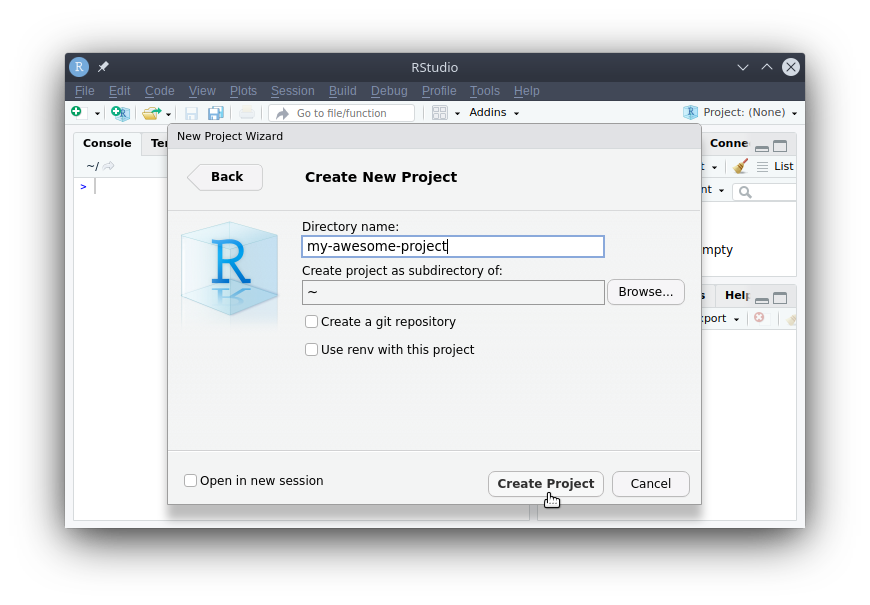
- Click “Create Project”.

Project created!
You have now successfully created the R project! Verify this by checking:
- The project name in the top right project dropdown
- The current working directory (
getwd()) is the project folder - The files pane shows the content of your project folder
Using R projects
There are multiple ways to open an R Project in RStudio:
- RStudio Project Selector:
Use the project selector dropdown in the top right corner to quicky switch between recent projects. - Opening the
.RprojFile:
Open the project’s.Rprojfile from your file explorer.
Any work you do while in this project will be restored when you next open the project (even unsaved files, but please don’t rely on this and save your work!).
You can close the project by simply closing RStudio (or via Project selector (top-right) → Close Project to keep RStudio open).
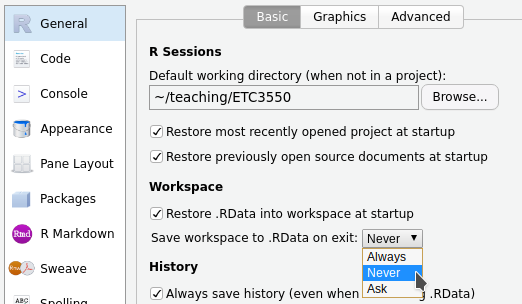
When you close your project you might be prompted to save your ‘workspace image’, to which we recommend you select Don’t Save.

Saving the workspace image? No!
While you should always save your work, it is best for reproducibility to not save your workspace image. Saving the workspace means next time you open the project, R Studio will also reload your last R session, along all of the variables and functions you previously created. While this seems convenient, it is better to explicitly load data and scripts each time you open a project to ensure that your analysis results can be re-run by anyone, including your future self.
You can prevent the popup messages by going to Tools → Global Options. Then select General on the side-bar and change “Save workspace to .RData on exit” to “Never”.
Project organisation

While an R Project helps you quickly switch between projects, it is up to you to organise your files into suitable subfolders within the project folder. By structuring your files effectively, you can reduce the risk of losing important data, simplify the code for accessing your data, and make it easier to locate each script.
File folders
A clear and consistent folder structure starts with sensible folder names. Here’s an example of a typical R Project directory structure:
my-awesome-project/
├── data-raw/ # Raw / unprocessed data files
│ ├── survey_results_2024.csv
│ ├── population_data.xlsx
├── data/ # Clean / processed data files
│ ├── survey_cleaned_2024.csv
│ ├── population_summary.csv
├── R/ # R scripts
│ ├── data_cleaning.R
│ ├── exploratory_analysis.R
│ └── model_fitting.R
├── outputs/ # Results, figures, tables, and other outputs
│ ├── figures/ # Graphs and charts
│ │ ├── age_distribution_plot.png
│ │ └── time_series_trends.jpeg
│ └── tables/ # Data tables and results
│ ├── regression_summary.csv
├── README.md # Project description and instructions
└── my-awesome-project.Rproj # R Project fileThis structure is suitable for most simple data analysis projects. We recommend you try to organise a few projects with this template before making modifications based on your personal preferences and project specific needs.
Expand For Recommended Folder Uses
data-raw/: This folder holds all original data files related to the project. Keeping raw and processed data separate ensures transparency and helps maintain data integrity.
data/: Save your tidy, clean and otherwise processed data here. This allows you to quickly read in analysis-ready data without needing to re-run your data cleaning script.
R/: Store all your R scripts here, we recommend the folder name “R” (to match the structure of an R package). More language-agnostic projects might use a “src”, “scripts”, or “code” folder. It’s a good practice to separate scripts into different categories depending on their function (e.g., data cleaning, analysis, modelling).
outputs/: This folder stores the outputs of your analysis, such as figures, tables, or models. You can have subfolders like
figures/andtables/to separate the different types of results. This makes it easier to find specific outputs and ensures that your working directory isn’t cluttered with unnecessary files.README.md: A README file is essential for documenting the purpose of the project, how to run the analysis, and any specific instructions for collaborators. This file helps others (and yourself, in the future) understand the project structure, dependencies, and key steps involved.
my-awesome-project.Rproj: This is the R Project file, which we created earlier. Projects help maintain your project’s workspace, settings, and set the working directory. It should always be kept at the root of the project folder.
Portable and reproducible projects
One of the key principles of maintaining an organised and reproducible workflow is to keep all project-related files within the project folder. This approach ensures that your project has:
Reproducibility: By keeping everything in one place, you ensure that your code can easily locate all the necessary files (data, scripts, outputs) using relative paths. This makes your analysis reproducible for anyone who accesses the project.
Portability: A self-contained project is portable, meaning you can move it to another computer, share it with collaborators, or distribute it with version control platforms (e.g. GitHub) without breaking any links or dependencies.
Organisation: Storing all files in one structured location helps avoid confusion and ensures you can quickly locate the resources you need.
R packages not included
R projects usually include everything except the R packages it depends on, which are instead usually found in the system’s global R environment.
This can cause reproducibility issues if the project is used on a system where some packages are missing, incompatible, or at different versions with different functionality. To address this, you can use the renv package, which bundles and manages package versions locally within the project folder. This ensures that your analysis always uses the correct versions of dependencies.
Check your understanding
What is the main benefit of using an RStudio Project?
How can you open an RStudio Project?
What happens to the working directory when you open an RStudio Project?
Which of the following files is typically included in an RStudio Project?
Which of the following is NOT true about RStudio Projects?
What should you avoid when closing an RStudio Project?
File Paths
When working with files in R, understanding and using file paths correctly is essential to ensure your scripts run seamlessly, whether on your computer or someone else’s.
File paths can be specified in two main ways: absolute paths and relative paths. Both approaches work to locate files, but they behave very differently when running your code on other computers. Appropriately specified file paths ensure that your projects will be portable to other people’s computers by enabling others to execute your analysis workflow without editing your scripts.
Absolute paths
An absolute path specifies the full location of a file or folder on your system starting from the root directory (e.g., C:/ on Windows or / on macOS/Linux).
Example:
# Windows
data <- read.csv("C:/Users/Admin/Documents/my-awesome-project/data/survey_data.csv")
# macOS/Linux
data <- read.csv("/home/Admin/Documents/my-awesome-project/data/survey_data.csv")Notice how the file path differs between operating systems? This is bad for reproducibility.
Absolute paths are NOT portable!
While absolute paths work on your computer, they are not portable because:
- They depend on the exact file structure of your system.
- If you share your project with others, their computer systems may not have the same directory structure.
- Moving your project to a new location can break the paths.
For these reasons, using absolute paths is strongly discouraged.
Relative paths
A relative path specifies the location of a file or folder relative to the current working directory. If you work within an [R Project]((#sec-projects), the current working directory is automatically set to the project folder, making relative paths the most reliable and portable option.
Example:
# Windows/macOS/Linux
data <- read.csv("./data/survey_data.csv")In this example:
./refers to the current working directory. It is optional../data/navigates to thedata/subfolder within the project folder.
Relative paths ensure that your scripts work regardless of where the project folder is located, as long as the folder structure remains consistent. This makes them ideal for reproducible analysis. 🎉
Finding files
When specifying file paths in R, you can use tab completion to quickly find and insert file paths. Inside quotation marks (““), start typing the folder or file name and press the TabTab key.
RStudio will then show a list of matching files and folders, making it easier to navigate your project, find files and avoid typos.
Working directories
The working directory in an R session is the folder from which R looks for files specified using relative paths. The working directory is almost always your project folder.
You can check your current working directory with the getwd() function.
This function returns the absolute path of the current working directory.
You can (but shouldn’t) change your working directory with setwd(). Instead, we strongly recommend using R Projects and relative paths from the project folder.
Working directory in R Markdown and Quarto
When running R Markdown or Quarto documents, the working directory is instead the location of the document. You can think of these documents as being their own mini-projects, where files paths to images and data are relative to the document.
If your document is in a sub-folder of an R project the relative paths can be confusing. R scripts will use the project folder, while your R documents will use the document folder!
Project paths
Another type of relative path is a project path, which specifies the location of files relative to the project folder (rather than the working directory). This can be useful since the project paths will work even if the working directory in R changes (e.g. when using code in R Markdown or Quarto documents).
.](resources/here.png)
The here package helps you create file paths relative to the project folder, ensuring that your scripts and analyses are portable and reproducible across different systems. The here() function automatically detects the project folder based on the location of your .Rproj file (or other indicators, like a README.md or .git folder).
Example:
# Windows/macOS/Linux
data <- read.csv(here::here("data/survey_data.csv"))In this example:
here::here()refers to the the project folder.data/survey_data.csvis the path to the dataset from the project folder.
Project portability
Since project paths are relative to the project folder, you will need to share the entire project for your code to be reproducible by others. Without the .Rproj file (or other project indicator), the here::here() package won’t know which folder is your project folder.
External paths
External paths refer to file locations external to the computer you are using but accessible over a network connection. External paths are specified with a URL (Uniform Resource Locator).
Example:
# Windows/macOS/Linux
data <- read.csv("https://startr.numbat.space/data/survey_results.csv")A URL consists of several parts:
- Protocol (
https://): The communication method used to access the resource. Most often this will behttporhttps(Hypertext Transfer Protocol Secure, the protocol for websites). Other protocols that are commonly used includeftp(File Transfer Protocol), ors3(Simply Storage Service). - Address / Location (
startr.numbat.space): The network address of the server hosting the resource. In this case,startr.numbat.spaceis the address, identifying the specific server to connect to.
- Path (
/data/survey_results.csv): The absolute path of the file or resource on the server. - Other Information: Sometimes additional details are needed to connect to the external server, commonly this is:
- A port number like
:8080specifies a network port (https://startr.numbat.space:8080/...).
- Credentials like
username:password@can provide login information (https://user:pass@startr.numbat.space/...).
- A port number like
Using external paths
Many R functions allow you to directly use web URLs for accessing data, for example read.csv() shown earlier. If the function you want doesn’t support external file paths, you can download the files with download.file().
download.file("https://startr.numbat.space/data/survey_results.csv", destfile = "data/survey_results.csv")
data <- read.csv("data/survey_results.csv")Check your understanding
Which of the following is an example of an absolute path?
Why should you avoid using absolute paths in R scripts?
What does the {here} package do?
Which of the following is NOT true about relative paths?
Which part of the URL specifies the communication method for the external resource?